AI 公司最怕的不是训练贵,而是每次回答都在烧钱
AI产品越受欢迎,公司越焦虑——推理成本像屋顶漏水,持续消耗算力。vLLM、TensorRT-LLM、llama.cpp三个开源项目分别从云端调度、硬件优化和本地部署入手,试图把“每token成本”降下来,让AI从烧钱走向赚钱。 你有没有发现一个很奇怪的现象。 AI产品越受欢迎,公司反而越焦虑。 传统软件公司最喜欢的一种模式叫规模效应。 一个SaaS产品开发出来之后,新增用户的边际成本很低。用户越
关于「KV Cache」的技术文章、设计资料与工程师讨论,持续更新。
AI产品越受欢迎,公司越焦虑——推理成本像屋顶漏水,持续消耗算力。vLLM、TensorRT-LLM、llama.cpp三个开源项目分别从云端调度、硬件优化和本地部署入手,试图把“每token成本”降下来,让AI从烧钱走向赚钱。 你有没有发现一个很奇怪的现象。 AI产品越受欢迎,公司反而越焦虑。 传统软件公司最喜欢的一种模式叫规模效应。 一个SaaS产品开发出来之后,新增用户的边际成本很低。用户越
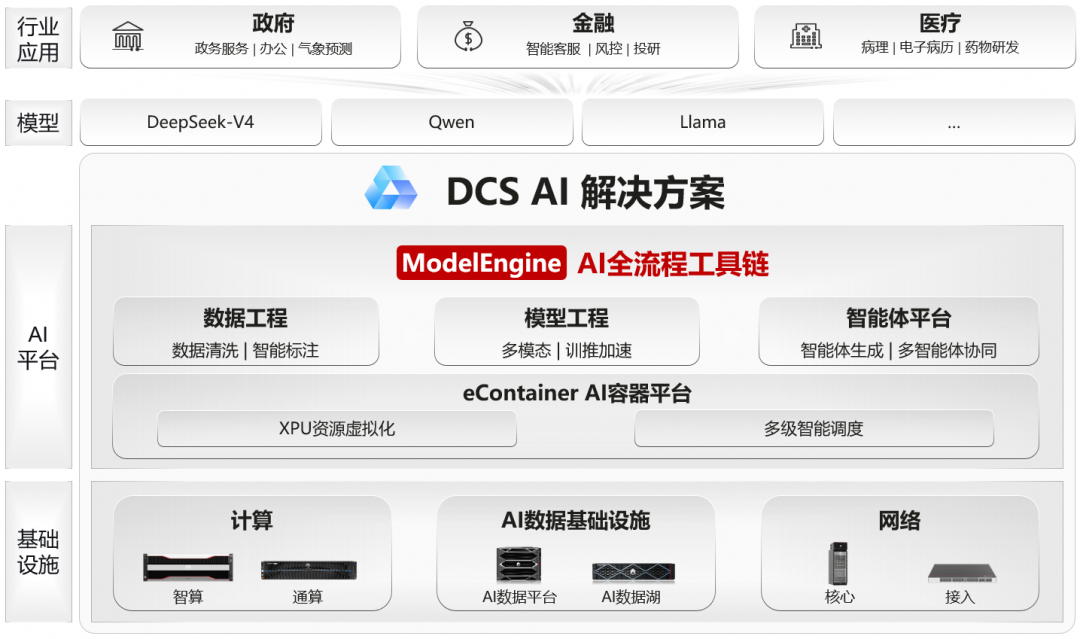
4月24日,DeepSeek-V4预览版正式推出并开源,将模型上下文窗口提升至1M,并引入KV Cache滑窗与压缩算法,有效缓解Attention计算复杂度与访存带宽压力,智能体能力大幅提高,在长序列推理与复杂任务处理中的表现更加高效与稳定,但新模型对基础设施也提出了新的挑战。华为DCS AI解决方案集成华为AI软硬件产品,发挥全栈优势,针对DeepSeek-V4进行深度适配,完成系统级优化和易

今日,DeepSeek-V4正式开源发布,将模型上下文窗口提升至1M,使模型在长序列推理与复杂任务链处理中的表现更加高效与稳定。华为AI数据平台深度适配DeepSeek-V4,将进一步推动大模型从实验阶段走向生产级应用。 DeepSeek-V4发布 带来KV Cache存储的全新挑战 DeepSeek-V4新版本支持100万Tokens的上下文能力。为提升上下文理解能力同时控制显存占用,DeepS
2026年4月24日,DeepSeek V4-Pro和DeepSeek V4-Flash正式发布并开源,模型上下文处理长度由原有的128K显著扩展至1M,实现近10倍的容量提升,首次增加了KV Cache滑窗和压缩算法,大幅减少Attention计算和访存开销,并通过模型架构创新更好地支持了Agent和Coding场景。昇腾一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇
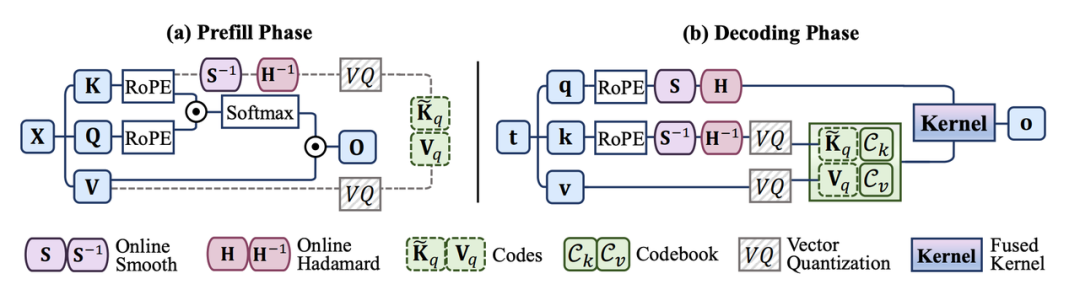
同样的GPU,推理速度提升8.3倍;80页合同,AI不用OCR就能读懂并回答问题——这些不是实验室PPT,而是小米AI团队刚拿到ACL 2026录用的7篇论文背后的真实技术突破。 ACL(Annual Meeting of the Association for Computational Linguistics)是计算语言学与自然语言处理领域国际公认的顶级学术会议,CCF-A类。本届会议将于20